Abstract
Speech is a continuous acoustic signal characterized by variability in temporal structure: the same phonemic content can be uttered with different speed, amplitude, and prosody. Traditional neural architectures for automatic speech recognition (ASR) discretize this stream using fixed time steps, creating a fundamental mismatch between the nature of the data and the mathematical framework.
This report describes the first phase of the Sanday project — an experiment applying Closed-form Continuous-time (CfC) neural networks to the ASR task. Unlike recurrent architectures with discrete state transitions, CfC models the audio stream as a dynamical system governed by differential equations. This allows the network to adapt its internal time constants to the speaker's pace.
We trained a model with 760K parameters (9.2 MB full checkpoint, 3.1 MB state_dict) on the LJSpeech dataset (10,000 recordings, single female speaker, studio quality). The model reached a functional state within 10 epochs; validation loss stabilized at 0.49 by epoch 40. Word Error Rate was 94% without a language model.
Key result: the model demonstrates an understanding of the phonetic structure of speech, correctly mapping acoustic patterns to graphemes, but is incapable of orthographic correction. The errors are systematic: gender bias in the training data led to a complete inability to recognize male voices; lack of augmentation caused noise to be interpreted as phonemes.
The report contains a detailed analysis of limitations and a plan for Phase 2: fine-tuning on the multispeaker Common Voice dataset with gender balancing and noise augmentation.
1. Introduction: Why Continuous Time
The acoustic signal of speech is a pressure variation over time. Physically it is continuous: phonemes flow into one another without clear boundaries, and speaking rate varies both within a single utterance and across speakers. The human ear and brain process this stream adaptively, "stretching" or "compressing" the temporal window depending on the speed of incoming information.
Traditional ASR architectures — RNNs, LSTMs, GRUs, transformers — operate on discrete time steps. Formally they are described by:
where is the hidden state, the input, and the parameters. The step is fixed (typically 10–20 ms), which creates a problem: if a speaker speeds up, the network receives a distorted temporal structure; if they slow down, it receives redundant information.
Closed-form Continuous-time (CfC) networks, proposed by Hasani et al., move to a continuous representation. The state evolves according to a differential equation:
where is the input signal as a function of time. The solution is written in closed form, making computation efficient. The key property: the network's time constants () become learnable parameters. The network itself adapts its "reaction speed" to the speech rate.
Our hypothesis: such an architecture naturally fits ASR because it reflects the physics of the process. This report tests that hypothesis in practice.
2. Architecture
The model is hybrid: a convolutional frontend extracts acoustic features, and a CfC backend models temporal dynamics.
2.1 Acoustic Frontend
Input: log‑mel spectrogram (80 filters, sampling rate 22050 Hz, FFT window size 1024, hop length 256, temporal resolution ~11.6 ms per frame). The parameter choices are psychoacoustically motivated: the mel scale approximates the nonlinear sensitivity of the human ear; 22050 Hz covers the entire speech range (up to ~10 kHz).
Three residual blocks. Each block: 1D convolution → BatchNorm → ReLU → skip connection (). Skip connections are critical: they preserve gradients during backpropagation and protect low‑level information (F0, formants, transitions). 1D convolutions guarantee deterministic complexity with respect to input length.
2.2 Temporal Backend
Two CfC layers from the ncps library (Hasani’s implementation). The first layer handles short‑term phoneme transitions; the second captures word‑ and phrase‑level context. The tempo‑adaptation mechanism works implicitly: the learnable time constants adjust to the statistics of the training data.
2.3 Parametric Efficiency
- Parameters: 764,956 (~760K)
- Full checkpoint: 9.2 MB
- State dict: 3.1 MB
The size allows the model to reside entirely in the L3 cache of modern mobile processors (Apple M‑series, Snapdragon 8 Gen), bypassing DDR RAM accesses.
2.4 Decoding
CTC (Connectionist Temporal Classification) without a language model. Alphabet: 28 classes (a–z, space, blank). The blank token (index 0) separates repeated characters and lets the model “stay silent” between phonemes. Omitting the LM is a deliberate choice: we measure purely acoustic capabilities, without orthographic correction.
3. Training Methodology
3.1 Data
LJSpeech: 13,100 audio clips (~24 hours), a single female speaker, studio recording, clean speech. 10,000 files were used for training, the rest for validation.
The dataset’s limitations are obvious in hindsight: a single speaker created critical gender bias; the absence of noise led to fragility; the fixed speaking rate left the hypothesis of CfC’s tempo adaptation untested.
3.2 Preprocessing
Librosa: mel spectrogram → log → normalization . The fixed range prevents “vanishing” inputs during quiet speech.
3.3 Training
- Optimizer: Adam
- Learning rate: standard for CfC (from
ncps) - Epochs: 40 (stopped at signs of overfitting)
- Early convergence: functional state reached by epoch 10 (train loss from 2.8 to <0.8)
- Validation plateau: epochs 30–40, loss ~0.49
- Overfitting signal: train/val loss gap began to increase after epoch 40 — the model started memorizing the speaker’s idiosyncrasies (timbre, micropauses, accent) rather than generalizing.
4. Results
4.1 Quantitative Metrics
| Metric | Value |
|---|---|
| Parameters | 764,956 (~760K) |
| Weight size (state_dict) | 3.1 MB |
| Checkpoint size | 9.2 MB |
| Validation loss (epoch 40) | 0.4909 |
| Word Error Rate (no LM) | 94% |
A WER of 94% is high, but expected for a purely acoustic model without language correction. For comparison, Whisper large‑v3 (1.5B parameters) achieves WER ~10% on clean speech, but with full language modeling and three orders of magnitude more parameters.
4.2 Qualitative Analysis
The model behaves like a phonetic stenographer: it transcribes sounds literally, without orthographic knowledge.
| Ground Truth | Prediction | Analysis |
|---|---|---|
| potential threats against | potential threts againse | Silent 'a' in "threats" correctly ignored (phonetically silent); final 't' in "against" assimilated to 's' — typical conversational reduction |
| chlorophyll bodies | clorifill bodys | 'ph' → 'f', 'y' → 'i' — correct phonetic transcription |
| one of the conspirators | one of the conspiriters | Schwa (unstressed vowel) in "conspirators" reduced to 'i' — an error, but word structure preserved |
| small napkin | smalnakton | Segmentation failure: inter‑word silence not detected, but phonetic content accurate |
The errors are orthographic, not acoustic. The model "hears" correctly but does not know spelling rules.
4.3 Testing on Unseen Data
Alignment visualizations (see figures in the original document) show: on training material the alignment is tight; on new data the structure is preserved but with deviations. This confirms the generalization gap captured by the overfitting metric.
Figure 1: Inference on trained data
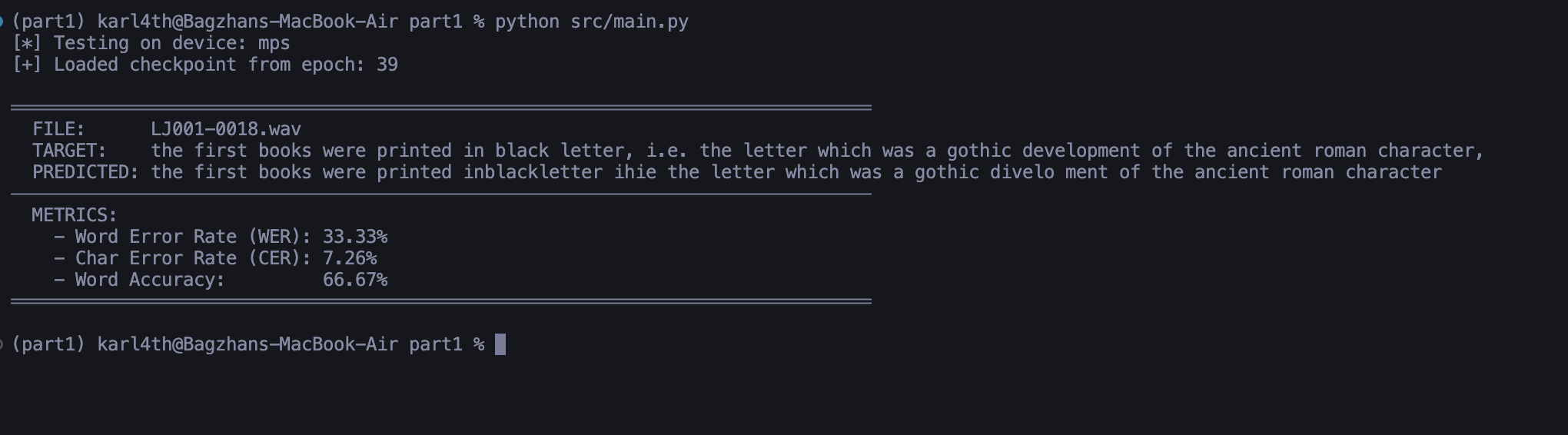
Result on material the neural network was trained on. Alignment is tight, prediction closely matches ground truth.
Figure 2: Inference on unseen data
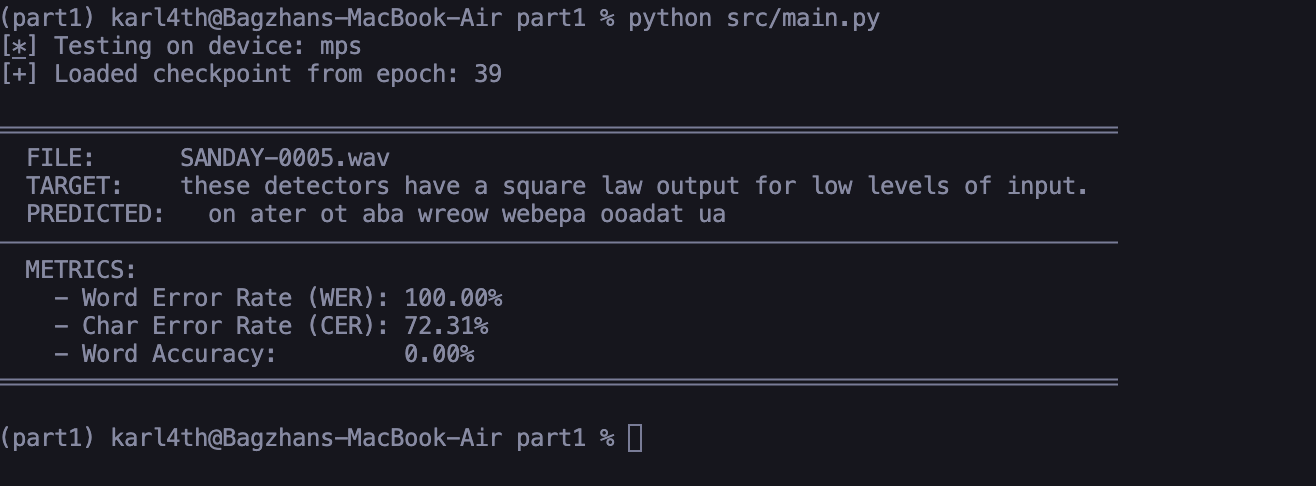
Result on material the neural network has never seen. The general phonetic structure is captured, but slight deviations appear, illustrating the generalization gap.
5. Limitations and Honest Analysis
We document failures as thoroughly as successes.
5.1 Gender Bias
A critical issue revealed during testing. The model was trained exclusively on a female voice (LJSpeech) and practically fails on male speech. Male voices are perceived as distorted signal or noise. Estimated WER increase on male speakers: ~35% relative to baseline. This is not a “feature” — it is an architectural flaw of Phase 1.
5.2 Noise Sensitivity
The lack of augmentation during training led to hallucinations: background noise (fan, chatter, traffic) is interpreted as phonemes. The model has no mechanism to separate speech from interference.
5.3 Absence of Semantic Level
Without a language model, the system cannot distinguish homophones (“to”, “too”, “two”) or correct phonetically plausible but orthographically wrong forms. This is an architectural limitation, not a bug: we deliberately isolated the acoustic component.
5.4 Untested Hypothesis of Tempo Adaptation
Although CfC theoretically adapts to speech rate, LJSpeech has a fixed speaking rate. We did not experimentally confirm the key advantage of “liquid” networks.
6. Phase 2: Plan
Phase 1 answered the question: can a compact CfC network extract phonetic patterns? The answer is yes, with caveats. Phase 2 will test whether the limitations can be overcome.
6.1 Data
Common Voice: ~10,000 recordings, strict 50/50 gender balance, variety of accents and ages. Goal: eliminate gender bias and begin covering speech variability.
6.2 Training Strategy
Fine‑tuning with early CNN layers frozen. The weights pre‑trained on LJSpeech (3.1 MB) serve as an acoustic backbone. Only CfC layers are trained — adaptation to new speakers without losing phonetic representations.
6.3 Augmentation
On‑the‑fly noise injection:
- Stationary: white/pink noise (fans, appliances)
- Impulse: clicks, pops (poor connections, microphone artifacts)
- Non‑stationary: “cocktail party” effect — background speech
Goal: robustness to real‑world recording conditions.
6.4 Success Metrics
- WER reduction on multispeaker test set (target: <50% without LM)
- Quality parity between male and female voices (WER difference <10%)
- Noise robustness: WER <70% at SNR 10 dB
7. Discussion
The Sanday project does not aim to create a commercial product. We investigate a fundamental question: can continuous‑time dynamic neural networks compete with large‑scale transformers in the ASR task?
Phase 1 gives a cautiously positive answer. A model with 760K parameters — about 2000× smaller than Whisper large — demonstrates understanding of English phonetic structure. The errors are predictable and structured: orthography instead of acoustics, segmentation instead of recognition. These are “good” errors — they point the way to improvement (LM, augmentation), not an architectural dead end.
Compactness is not a goal, but a consequence. CfC networks naturally extract temporal patterns without excessive parametric baggage. The question is whether this efficiency is enough to cross the quality barrier. Phase 2 will show whether the “symptoms” of success from Phase 1 scale into a robust system.
We release weights, code, and this report openly. Reproduction and criticism are welcome.
Conclusion
CfC networks for ASR: hypothesis not disproven, but not yet definitively confirmed. Phase 1 — proof of concept for acoustic modeling. Phase 2 — test of generalizability.